登录地址:http://cata.yue-zhi.com
产品简介:
古籍数字化工作目前亟需加强基础设施建设,这部分工作由古籍目录库、古籍图文库和古籍知识库三部分组成。目前古籍图文库发展比较突出,经过二三十年的建设,商业数据库领域已经有爱如生、书同文、雕龙、鼎秀等古籍数据库能提供几万种古籍的图文服务,而中国国家图书馆、日本国立公文书馆、美国哈佛燕京图书馆等也建设了包含数万种古籍图像的数据库,“中华古籍智慧化服务平台”“识典古籍平台”等也宣称在几年内提供数万种古籍图文库,还有“全球汉籍影像开放集成系统”提供古籍图像库的检索发现功能,可以说这些已经能够满足研究的基本需求。面对这些数量浩瀚的典籍,亟需能够联合导航的古籍目录总库。目录是读书治学的门径,王鸣盛《十七史商榷》卷一中的总结最为精当:“目录之学,学中第一要紧事,必从此问途,方能得其门而入。”已有的古籍目录库不能很好地支撑古籍图文库的建设与应用,同时,古籍目录库本身也没有发挥出数字古典目录学的功用,更好地支撑古典文献学研究。另一方面,古籍目录数据作为文献知识内容也是古籍知识库建设的重要组成部分。这就是亟需建设覆盖全面的古籍目录总库的意义所在。
在古籍数字化浪潮中,“图文易得,目录难寻”已成为学者研究的核心痛点。面对数万种古籍图文库缺乏分类导航、现有目录库数据零散且非结构化、难以支撑进一步的数字人文研究,“阅藏知津——中国历代典籍目录总库”(以下简称“阅藏知津”)应运而生。本数据库由资深学术团队领衔设计,基于以往的系统开发经验,致力于打造全球首个覆盖全面化、数据结构化、功能智慧化的中国古籍目录数字人文平台,推动古典目录学走进数字时代。
一、核心架构:三大子库协同赋能
“阅藏知津”以“中国历代典籍总目库”(以下简称“总目库”)、“中国历代编撰目录库”(以下简称“编撰库”)、“中国历代典藏目录库”(以下简称“典藏库”)为支柱,目前已构建“总目资源——成书分析——典藏分析”三位一体的目录数据知识平台,实现中国古籍遗产的系统性盘点与时空动态解析。
(一)总目库:古籍遗产的“全景地图”
1. 数据规模与权威性
总目库以《中国古籍总目》为基础,第一期整合正史艺文志(从《汉书·艺文志》至《清史稿·艺文志》)、《四库全书总目》等核心目录,收录25.4万种典籍(包括现存典籍近20万种,亡佚典籍近6万种)。通过独创的“丛书子目析出”处理,解决如《野菜博录》《救荒活民书》等长期埋没于丛书中的典籍独立著录问题,并实现各目录重复品种的归一化认同。第二期整合历代艺文志补编数据,第三期整合地方文献、专科目录数据,目前预估我们可知的历代典籍品种数量在35-40万种(现存约20万种)。
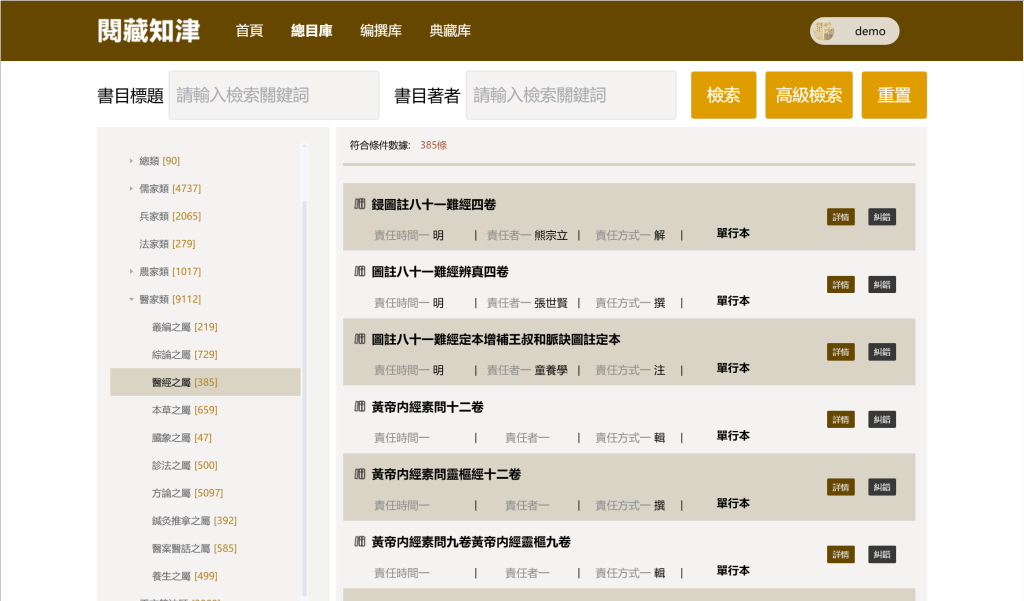
图:总目库分类导航示意图
2. 核心功能
智能导航:按《中国古籍总目》分类体系逐级浏览。
多维导览:古籍著录显示其品种、版本和收藏等信息,逐步实现一键链接或揭示典籍的相关资源:如网上馆藏图像、商业数据库、影印出版等收录情况。(后期功能)
提要揭示:逐步聚合揭示《四库总目提要》《续修四库总目提要》等提要资源,以及分散在整理本中的整理说明,利用数智时代的便利为《中国古籍总目提要》编撰汇总参考资料。(后期功能)
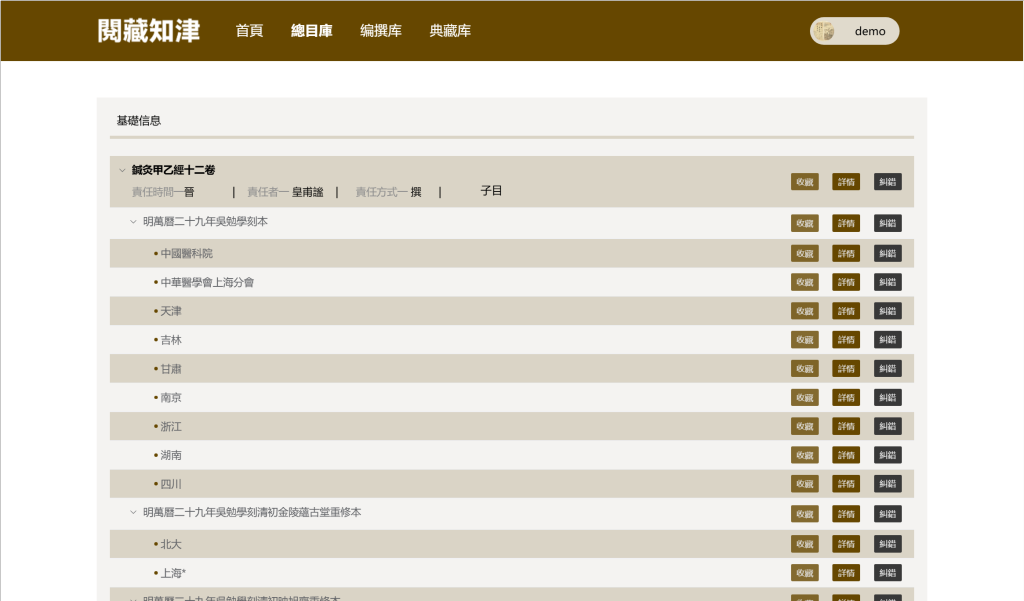
图:总目库著录信息和资源链接示意图
(二)编撰库:学术生产的“时空透镜”
1. 创新设计
编撰库是将总目库数据按编撰时代重组,在持续细粒度加工的基础上,构建典籍成书时序图表。
2. 核心功能
学术史可视化:选定分类(如“子部·医家类”),自动生成该类典籍的成书按朝代统计的数量柱状图,直观揭示学术生产脉络。
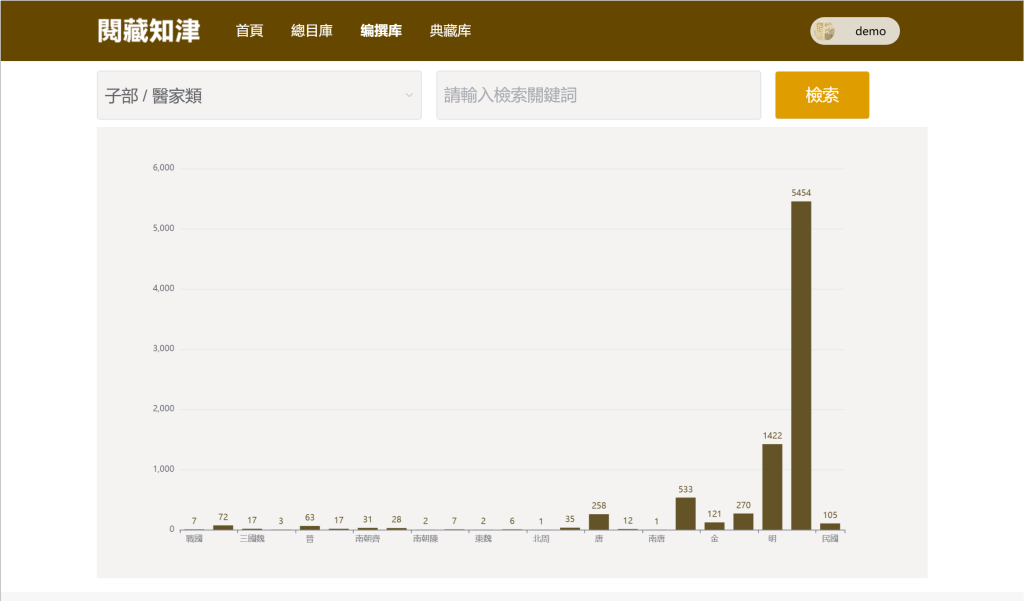
图:编撰库学术史分析示意图
精细化编年:未来融合各种典籍编撰年表、学术编年、学者年谱等数据,将编撰时间加工到30年左右区间,未来支持作者、学派、地域等著作年表生成,以及支持著作地域分布表的生成。
3. 学术价值
编撰库可为学术史、思想史、文化史研究提供量化工具,解答“何时何地产生何种知识”的学术问题。
(三)典藏库:典籍流传的“追踪雷达”
1. 数据根基
典藏库第一期结构化加工29部历代藏书目,涵盖20万条典藏记录,将七史艺文志、《四库总目》以及重要的公私藏书目,如《崇文总目》《秘书省续编到四库阙书目》《中兴馆阁书目》《文渊阁书目》《内阁藏书目录》《天禄琳琅书目》《郡斋读书志》《直斋书录解题》《遂初堂书目》《菉竹堂书目》《百川书志》《宝文堂书目》《脉望馆书目》《澹生堂藏书目》《千顷堂书目》《绛云楼书目》《述古堂藏书目》《传是楼书目》《天一阁书目》等纳入典藏谱系。
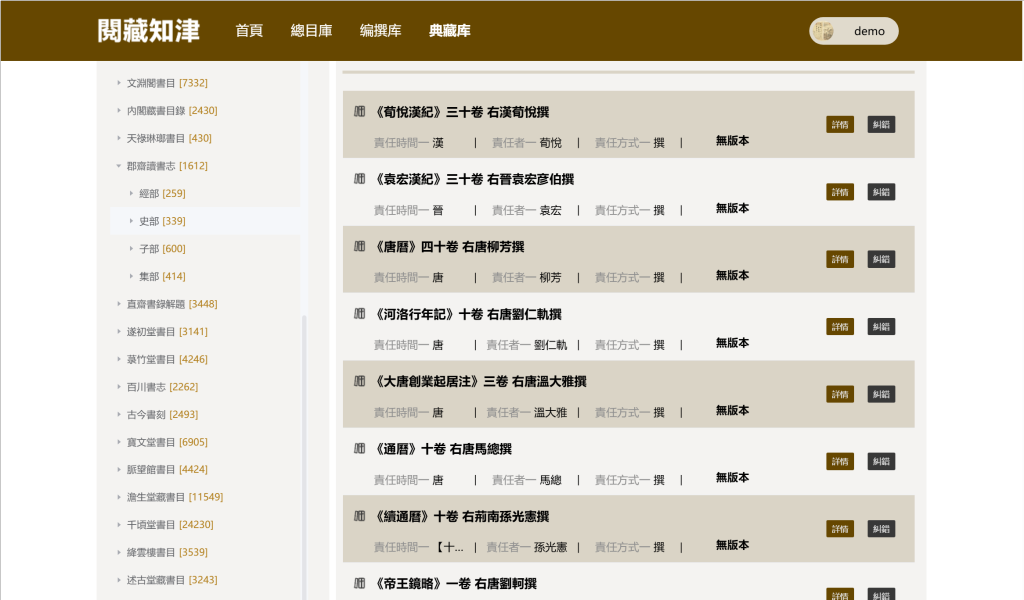
图:典藏库书目导览示意图
目前估计现存历代古籍典藏目录(民国以前)约有1000种,我们将按照目录的重要性分批加工入库,构建历代古籍典藏资源总库。
2. 颠覆性功能
历代典藏揭示:检索某书(如《贞观政要》),一键生成其千年收藏轨迹,展现历代典藏概况。
历代典藏汇总分析:未来可按时代/藏家/地域等浏览,揭示典籍时空分布(如“明万历江南藏书”)。
3. 联动价值
补充总目库缺收典籍(如官私藏目录所载稀见典籍)。
根据最后著录典藏目录成书时间推算典籍亡佚时间,未来将数据补充到编撰库中,编撰库升级为“历代典籍兴衰分析库”。
二、突破性价值:数字古典目录学的成立
(一)从“平面著录”到“立体知识网络”
1. 数据深度结构化
“阅藏知津”不仅是工具升级,更是研究方法的革新。在数据库中,书名、作者、版本、藏印等字段被结构化为可计算单元,并经过标准化和归一化,支持瞬时生成“宋版目录”“清代批校本目录”等定制索引。
2. 关系化赋能
“阅藏知津”关联人物库,可以生成诸如“浙江籍学者著作目录”“苏州刻工经手刻本”等知识网络;“阅藏知津”对接图文库,目录条目可以直通全文图像、篇卷乃至语段。
(二)革新传统目录学
1. 自动目录编纂
在“阅藏知津”,通过主题词等标引,自动聚类生成“水利文献专题书目”“女性著作总目”,突破人工编纂局限。
2. 支撑宏观书籍史研究
利用典藏库数千“时空截面”,分析典籍传播与学术思潮、地域文化的互动机制,弥补中国书籍史微观史料不足的短板。
3. 数字人文的“真实需求”响应者
“阅藏知津”可以解决学者的真实需求,利用编撰库替代人工统计历代成书数据,省时90%;利用典藏库可以秒级完成需长时间梳理的典籍流传数据。
“阅藏知津”还具有一定的示范性意义,它证明数字人文可深度嵌入传统人文研究环节(如目录学、书籍史),推动人文研究范式转型。
三、建设进程
当前阶段(2025年上半年):总目库第一期(25万条)、编撰库(朝代粒度分析)、典藏库(29种藏书目)开放试用。
未来规划:总目库分三期建成、典藏库数据分五期建成,各期三个子库适当推出若干新功能。
“阅藏知津”完成了古籍目录数据加工的结构化、同一化、标准化、关系化。它不仅是中国历代典籍的“超级导航仪”,更是数字古典目录学的奠基工程。通过三大子库的协同创新,本数据库将重塑学者理解典籍、探索文脉的方式,推动中华典籍文化遗产在数字时代迸发新生命,支撑数字人文研究的革新与探索。